Employee with slide rule, Hercules Powder Co. Experiment Station, Wilmington, DE
A little over a week ago the Australian Electoral Commission (AEC) published the preference tickets for the Federal election. Every party has to lodge with the AEC how they would like their votes to be distributed for people that vote above the line in the Senate.
Of course, this is of fascination to political insiders, because preference flows can make the difference between winning and losing a seat. But to normal people, it’s virtually meaningless.
My guess is if you’re the kind of person that would look at how the parties are selecting their preferences you’re also the kind of person who might vote below the line. If all seems like it’s too geeky and too complicated, then voting above the line is the way to go and you’re leaving it to trust that something sensible happens with your voting preferences.
For the first time this year, on Sunday, I found myself looking through the preference tickets. I wanted to check for myself what people on Twitter were saying about how the Wikileaks party had preferenced.
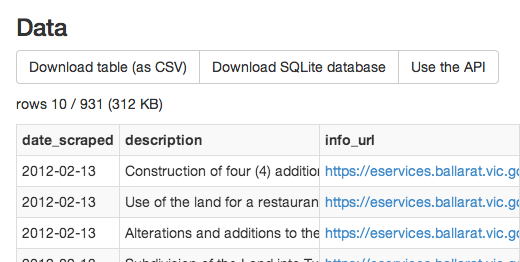
You’re confronted by pages and pages of boxes with numbers. Here’s just one of 105 pages showing part of the Carers Alliance ticket and this just for New South Wales.

Something really struck me. This is an invaluable source of information, yet it’s almost completely indecipherable. There are so many candidates and parties. So many relationships between parties, both public and hidden but in these preferencing arrangements it’s all there. It’s just a matter of squeezing some meaning from these pages and pages of boxes with numbers.
I was reminded of the Eurovision Song contest.
Eurovision isn’t really about songs. Well maybe it is. No, it is about songs, but who wins and which countries vote for which other countries seems to have very little to do with the songs. It’s a fascinating insight into the shifting relationships between european neighbours, that mixture of politics and geography.
Something I’ve been wanting to do for years, but never quite managed to find the time to do is to analyse the voting behaviour and visualise the result in a very specific way. The idea is as follows. You look at how one country votes for another country. You use that vote to create some measure of “distance” between the countries. In this case, the higher the score they give each other, the lower the distance between the two countries. Then, with the distance data, would it be possible to create a new “geopolitical” map of Europe? It would show the countries arranged so that the distances between them map to the distances calculated from the Eurovision Song contest scores.
Where else do you get to see every country voting on every other country. That is such a rich data set.
You only have to look at Turkey’s chequered Eurovision history, including minor scuffles with Greece to see this happening.
How would this geopolitical map compare the physical, normal map of Europe?
How would this map change over time?
I think this would be fascinating to look at. I hope I’ll get there one day (unless someone’s done it already, of course!)
The Setup
Back to Australia. What if we applied the same idea to the voting preference data?
We can create a map that shows the relationship between parties. Parties that are close on the map have preferenced each other above those that are further away.
At this point I’ll get into some nitty gritty of how I went about getting the data and transforming into a form where it could be used to generate a map. We’ll start with a simplified example so you can follow through the reasoning. The punchline comes towards the end of the post when we apply the technique to the real data.
First off a big thank you to Benno Rice, from belowtheline.org.au, who has already done the job of gathering the vote preferencing data from the AEC and republishing it in a sane digital format.
If you haven’t yet looked at his site, please do. It’s really important. It makes it much easier to vote below the line by allowing you to reorder the candidates in your browser and then print out a personal PDF with your choices that you take with you to the ballot box.
Let’s first dive in with some made up data and a simplified situation. So, let’s for the time being ignore the fact that groups, which can consist of multiple parties, preference individual candidates. Let’s just say that parties preference other parties.
Say you have four parties A, B, C and D that have preferenced other parties as follows:
| Position |
A |
B |
C |
D |
| 0 |
A |
B |
C |
D |
| 1 |
C |
C |
A |
C |
| 2 |
B |
A |
B |
A |
| 3 |
D |
D |
D |
B |
(table 1)
In each case the party has preferenced their own party first. No surprises there.
Our goal is to assign “distances” between each party based on their preferences. Party A has a preference order of A, C, B, D. The first party A, we’ll assign a distance of 0. The second party C a distance of 1 away from A.
Following that through with each pair of parties and arranging that in a new table we get the following:
| distances |
A |
B |
C |
D |
| A |
0 |
2 |
1 |
2 |
| B |
2 |
0 |
2 |
3 |
| C |
1 |
1 |
0 |
1 |
| D |
3 |
3 |
3 |
0 |
(table 2)
There’s one last thing we need to do to make this table work. That matrix should be symmetric. In other words, the distance from B to C should be the same as the distance from C to B. That’s how real distances work so we need our measure of distance to do the same.
Ideally it would be great if we could tweak the distance numbers so that the matrix becomes symmetric and we keep the absolute ordering of the items in the list.I couldn’t figure out an easy way of doing this. So, instead I opted to do the dumb thing which is just average the two distances, which for the matrix means taking the matrix above and averaging with its transpose. That will give a symmetric matrix.
What that means intuitively is that the distance between two parties is equally affected by the relationship in each direction.
| symmetric distances |
A |
B |
C |
D |
| A |
0 |
2 |
1 |
2.5 |
| B |
2 |
0 |
1.5 |
3 |
| C |
1 |
1.5 |
0 |
2 |
| D |
2.5 |
3 |
2 |
0 |
(table 3)
Phew. Nearly there.
So, now how do we find points given the distances between them? I’ve known about a bunch of ways of solving this for a while but I found a new one in the course of looking at this and it’s already implemented in the R statistics package. The technique is called multidimensional scaling (MDS) and essence what it does is find points (in a given dimensional space) that overall best match the given distances between them.
There are a few variants of the method. The most important distinction is between metric and non-metric multidimensional scaling. Metric MDS tries to fit the distances as best it can, treating the distances as the exact distances it’s trying to fit. Non-metric MDS just tries to maintain the order of the distances. In our case, we’ve made the distances up based on an order in a preference ticket. So, non-metric MDS is the obvious choice.
There’s an infinite number of solutions that are just translated or rotated versions, but we’re just interested in finding one.

What’s fabulous about this is that it’s turned a bunch of abstract numbers on preference tickets into something tangible and comprehensible. You can now see the relationship between the parties.
Right away you can see the importance of party C. It’s being highly preferenced by the other parties. Of course, you can easily see that from the table. We’re just demonstrating a point here.
Look at the preferencing between parties C and D. From table 1 you can see that party C is preferencing D last while party D is preferencing C first. Remarkably this can be seen in the calculated layout of the parties. D is the furthest away from C while the situation is very different for D where C is the closest of the parties because it’s sitting there on its own out on the right.
To really have confidence that this makes sense, let’s go back and figure out the preference tickets from the coordinates of the parties that we’ve calculated. This is just a consistency check.
First thing, using the calculated coordinates we calculate the matrix of distances between the points.
| fitted distance |
A |
B |
C |
D |
| A |
0 |
1.7 |
0.7 |
2.6 |
| B |
1.7 |
0 |
1.2 |
3.0 |
| C |
0.7 |
1.2 |
0 |
2.2 |
| D |
2.6 |
3.0 |
2.2 |
0 |
(table 4)
This matches up reasonably well with table 3. Since we’re using non-metric multidimensional scaling we wouldn’t actually expect this to be the same. Now given those distances what would the preference tickets look like with each party voting for the other parties in order of how far away they are?
| A |
B |
C |
D |
| A |
B |
C |
D |
| C |
C |
A |
C |
| B |
A |
B |
A |
| D |
D |
D |
B |
(table 5)
And you know this is exactly the same as table 1. That means this has worked. Woohoo!
Applying this to the real data
The real world Senate preferencing data is of course more complicated than the simplified situation we just went through.
- Not every candidate is a member of a party
- A group might have several independents or parties in it
- Groups preference candidates not parties
- A group can lodge several tickets
The first one is pretty easy to deal with. We’ll just completely ignore independents. We’ll effectively remove them from the preference ticket before we do any of the other calculations.
2. only happens with the coalition. So, there we treat all the parties that are members of the coalition as being members of the “coalition” party.
3. is a little more complex. Say a party (A) preferences candidates as follows:
| Position |
Candidate |
Party |
| 0 |
Alice |
A |
| 1 |
Bob |
A |
| 2 |
Carol |
B |
| 3 |
Dan |
C |
| 4 |
Eve |
B |
| 5 |
Frank |
D |
(table 6)
Their parties are shown in brackets. I started off by taking the average position for each party. In this case that would be:
| Distance (from Average Position) |
Party |
| 0.5 |
A |
| 3 |
B |
| 3 |
C |
| 5 |
D |
(table 7)
But doing this has a couple of problem. First if a party has multiple candidates that it puts first then it will end up with a non-zero distance to itself. Not good. The second issue is that the number of candidates in a party will affect the overall distances. The more candidates the further away it will be.
A better approach is to only consider the highest preferenced candidate for each party. That gives the following positions. The number of candidates makes no difference to the distances
| Distance (from first position) |
Party |
| 0 |
A |
| 1 |
B |
| 2 |
C |
| 3 |
D |
(table 8)
Issue 4. is handled by simply averaging between the multiple tickets.
The Results (The Reveal)
Using the ideas from the last section, the data from the AEC via belowtheline.org.au and some Ruby scripts for munging the data and calculating the distances we can see the party relationship for each State and Territory.

You can see three distinct clusterings. The top which consists of the Coalition, Katter’s Australian Party, Palmer United Party; the right hand side which consist of the ALP, Greens, Socialist Alliance, Pirate Party and Wikileaks; The rest in an arc around the bottom are largely single-issue parties.
There’s a noticeable crescent shaped left hand arc. It’s almost as if the parties in this arc are defining themselves to a large extent by their opposition to the group in the centre of the arc.
There are definite clustering of socially conservative right, libertarian right, socially conservative left and libertarian left but it would be simple-minded to suggest that the layout is following that simple categorisation. You can see surprising relationships. I would be interested to hear from people with more knowledge than myself of the minor parties what this shows.
I also can’t help notice that the Voluntary Euthanasia party is very close to the Stable Population Party.
It’s important to remember not to place any meaning on the absolute distances between parties. All that matters and all that is meaningful is the relative distances, i.e. whether one party is further away than another party. If a party is twice the distance away as another party that does not mean that is half as closely connected. All you can say is that it is less connected.
Let’s do the same for the other States and Territories
Posted in Development
| Tagged Australian Electoral Commission, Benno Rice, federal election, Multidimensional scaling